データの読み込み
データをバッチまたはバルクで、データレイクやウェアハウスなどのターゲット送信先に読み込みます。 Workatoは、さまざまな送信先にデータを読み込むための多様な設計パターンをサポートし、データを分析やレポート作成に利用できる状態にします。 このセクションでは、Workatoのデータ読み込み機能を活用して、データオーケストレーションプロセスを最適化する方法について説明します。
Snowflakeコネクターアクション
Workatoは、さまざまなアクションを使用してSnowflakeにデータを読み込むための包括的なサポートを提供します。 これらのアクションを使用すると、レコードの挿入、更新、アップサート、削除を効率的に実行できます。 詳細な手順については、次のアクションを確認してください。
- 行をバッチ選択アクション
- 行を挿入アクション
- 行を更新アクション
- 行をアップサートアクション
- 行を削除アクション
- カスタムSQLを使用して長時間クエリを実行アクション
- カスタムSQLアクションの実行
- クエリ結果をエクスポートアクション
- 内部ステージにファイルをアップロードアクション
- ステージからテーブルにバルク読み込みアクション
- 行をレプリケートアクション
- スキーマをレプリケートアクション
- 行をマージアクション
サンプルレシピ: SalesforceからSnowflakeへのデータのバッチ読み込み
このレシピでは、Workatoのバッチ読み込み機能を示します。 Salesforceから新しいリードをバッチでエクスポートし、データをSnowflakeに読み込みます。
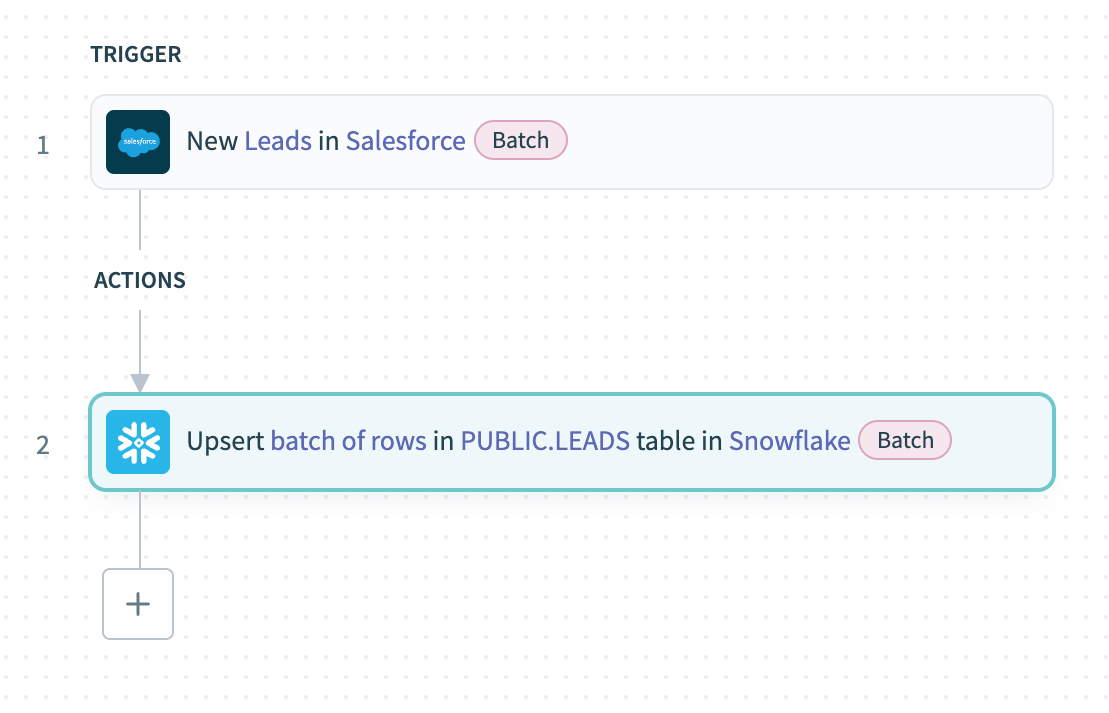 Snowflakeへのバッチ読み込み
Snowflakeへのバッチ読み込み
レシピのウォークスルー
SalesforceのNew records batchトリガーを設定し、新しいリードをバッチでエクスポートします。
SnowflakeのUpsert rows batchアクションを使用して、Salesforceからのリードリストの出力データピルをバッチでRows source list入力にマッピングし、新しいレコードをアップサートします。
SQL Serverコネクターアクション
Workatoは、さまざまなアクションを使用してSQL Serverにデータを読み込むための包括的なサポートを提供します。 これらのアクションを使用すると、レコードの挿入、更新、アップサート、削除を効率的に実行できます。 詳細な手順については、次のアクションを確認してください。
- 行をバッチ選択アクション
- カスタムSQLを使用して行をバッチ選択アクション
- 行を挿入アクション
- 行をバッチ挿入アクション
- 行を更新アクション
- 行をバッチ更新アクション
- 行をアップサートアクション
- 行をバッチアップサートアクション
- 行をバッチ削除アクション
- 行をバッチレプリケートアクション
- オンプレミスファイルからバルク読み込みアクション
- カスタムSQLを実行アクション
- カスタムSQLを使用して長時間クエリを実行アクション
- ストアドプロシージャを実行アクション
- クエリ結果をエクスポートアクション
サンプルレシピ: SalesforceからデータをバルクフェッチしてオンプレミスSQL Serverに読み込み
次の例では、バルクフェッチを使用してSalesforceから販売注文データを抽出し、オンプレミスSQL Serverに読み込みます。
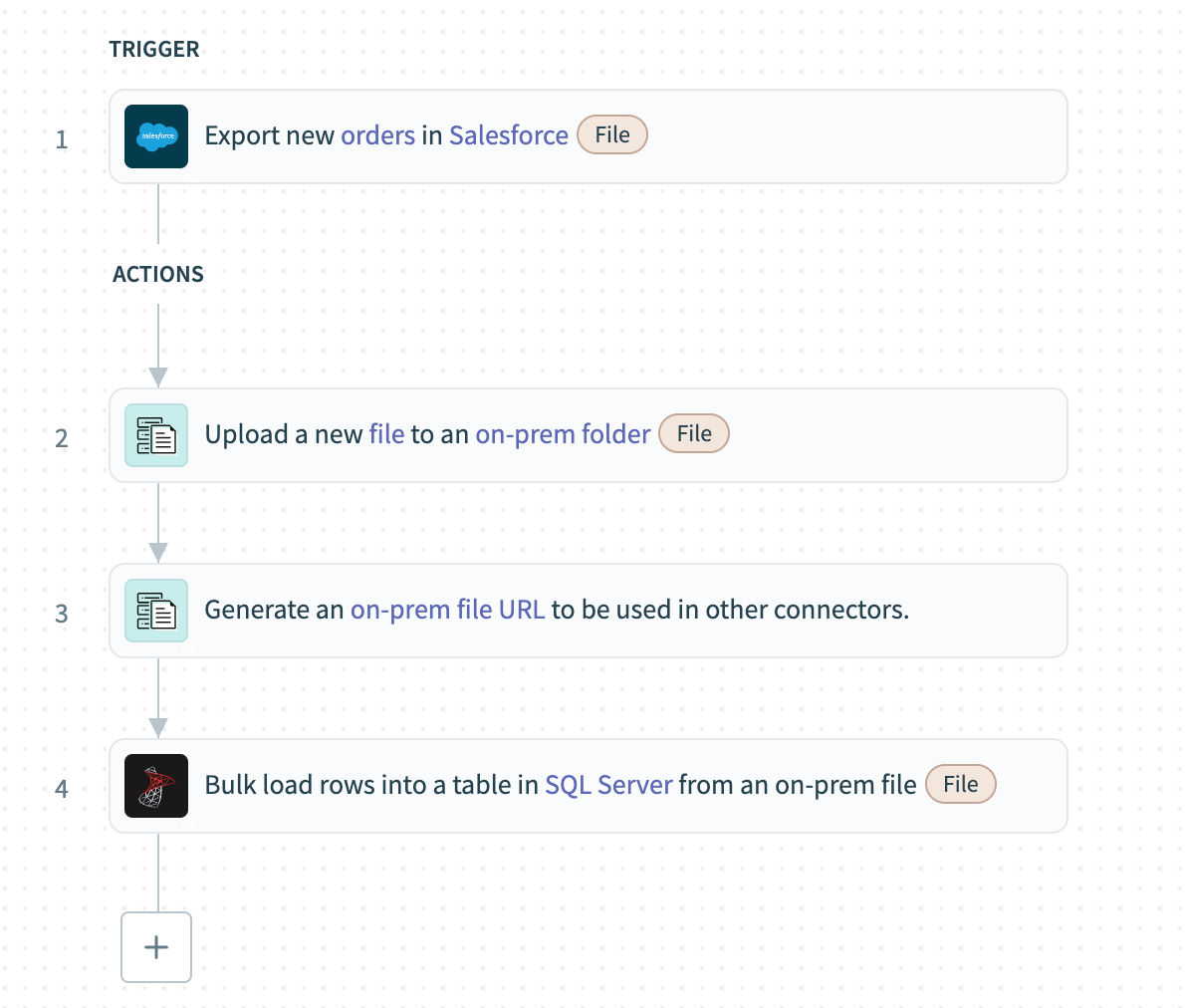 SalesforceクラウドからバルクフェッチしてオンプレミスSQL Serverに読み込み
SalesforceクラウドからバルクフェッチしてオンプレミスSQL Serverに読み込み
レシピのウォークスルー
Export new records in Salesforce (bulk) トリガーを設定して、Salesforceから新規作成されたレコードをCSVデータとして一括取得します。
オンブレミスファイル - Upload fileアクションを使用して、CSVデータをオンプレミスフォルダに読み込みます。
オンブレミスファイル - Generate on-prem file URLアクションを使用して、オンプレミスシステムで作成されたCSVファイルのURLを生成します。
前のステップで生成されたURLをSQL Server - Bulk load from an on-prem fileアクションにマッピングします。 このアクションはオンプレミスフォルダからファイルを取得し、テーブルに直接読み込みます。
サンプルレシピ: SQL ServerからAmazon S3へのデータのバルク読み込み
次の例では、バルク読み込みを使用してSQL Serverからデータを抽出し、Amazon S3に読み込みます。
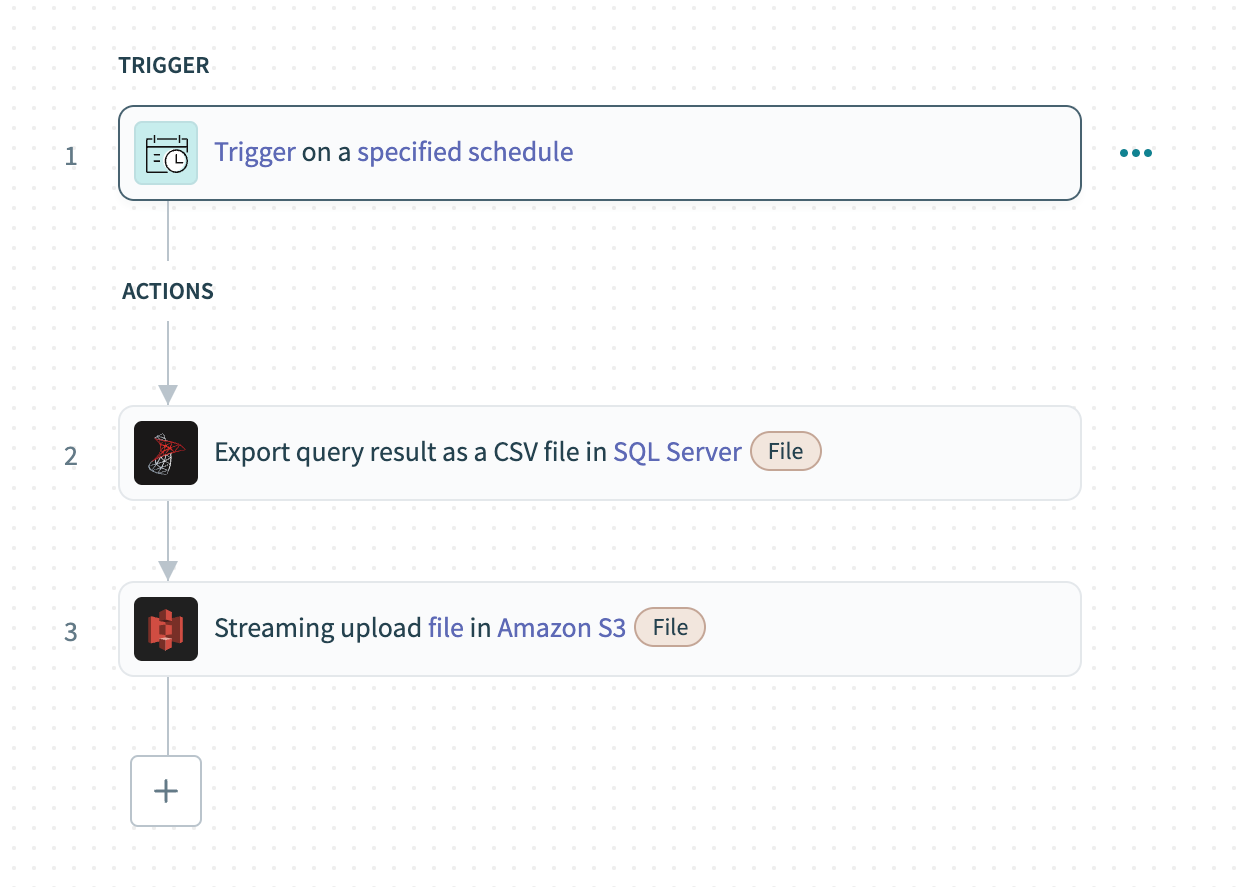 SQL ServerからAmazon S3へのデータのバルク読み込み
SQL ServerからAmazon S3へのデータのバルク読み込み
レシピのウォークスルー
Schedulerトリガーを設定し、データをバルク読み込みする頻度を決定します。
SQL ServerのExport query resultアクションを使用して、データベースでカスタムSQLクエリを実行し、結果をCSVファイルとしてバルクでエクスポートします。
前のステップのファイルの内容をAmazon S3のUpload file streamingアクションにマッピングし、データをストリーミングしてクラウドストアにアップロードします。
サポートされているコネクター
次のコネクターはバルクアップロードをサポートしています。
すべてのファイルコネクター:
- オンブレミスファイル
- Workato FileStorage
- SFTP
- FTP/FTPS
- Google Drive
- Microsoft OneDrive
- Microsoft Sharepoint
- Box
- Dropbox
- BIM 360
- Egnyte
すべてのデータレイクコネクター:
増分読み込み
増分読み込みを使用すると、フル読み込みのオーバーヘッドを発生させずに、ターゲット送信先のデータを最新の状態に維持できます。 これには、多くの場合、タイムスタンプ、バージョンキー、またはトリガーを使用してソースデータの変更を追跡し、前回の読み込み以降に追加または変更されたデータのみを読み込むことが含まれます。 この戦略は、リアルタイムのデータオーケストレーションとシステムリソースへの影響の最小化に不可欠です。
最終更新日: