データのロード
データレイクやデータウェアハウスなどのターゲット先に、バッチまたは一括でデータをロードします。Workatoはさまざまなデスティネーションへのデータロードのための多様なデザインパターンをサポートしており、分析やレポーティングの準備が整ったデータを確保します。このセクションでは、Workatoのデータロード機能を活用してデータオーケストレーションプロセスを最適化する方法を紹介します。
Snowflakeコネクタのアクション
Workatoは、さまざまなアクションを使用してSnowflakeへのデータロードを包括的にサポートします。これらのアクションにより、レコードの挿入、更新、アップサート、削除を効率的に行うことができます。詳細な手順については、以下のアクションを参照してください:
- 行を選択するバッチアクション
- 行を挿入するアクション
- 行を更新するアクション
- 行をアップサートするアクション
- 行を削除するアクション
- カスタムSQLを使用して長いクエリを実行するアクション
- カスタムSQLを実行するアクション
- クエリ結果をエクスポートするアクション
- ファイルを内部ステージにアップロードするアクション
- ステージからテーブルにバルクロードするアクション
- 行をレプリケートするアクション
- スキーマをレプリケートするアクション
- 行をマージするアクション
サンプルレシピ:SalesforceからSnowflakeへのバッチデータロード
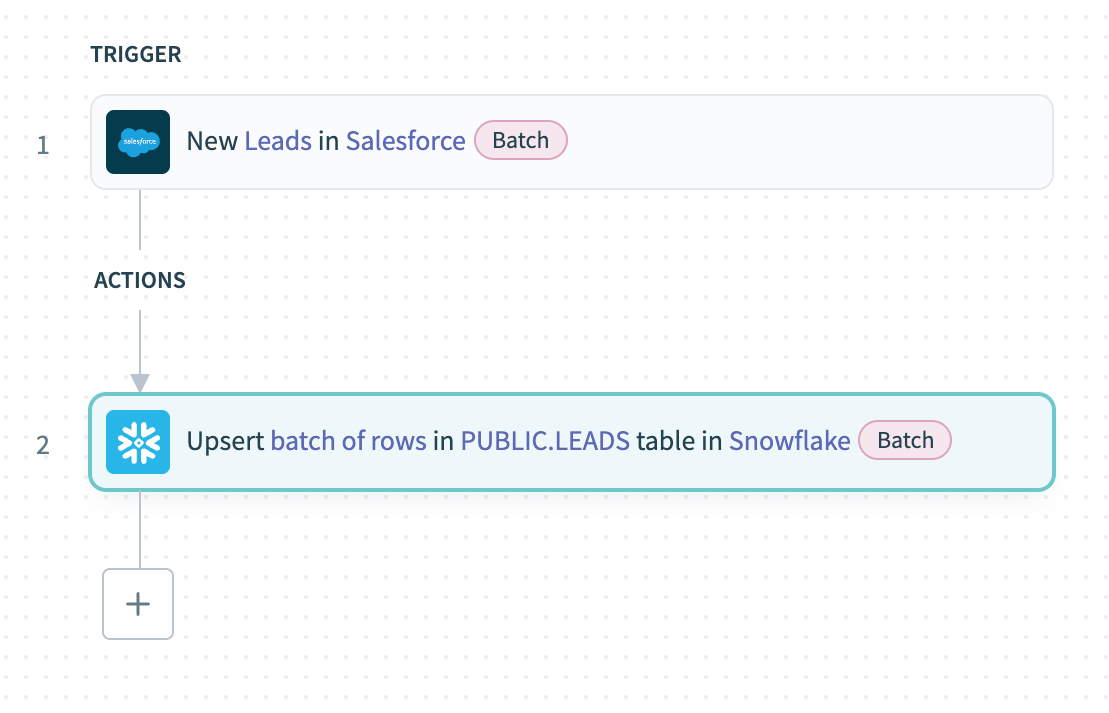
このレシピでは、Workatoのバッチロード機能を示しています。Salesforceから新しいリードをバッチでエクスポートし、そのデータをSnowflakeにロードします。
 Batch load into Snowflake
Batch load into Snowflake
レシピの解説
SalesforceのNew records batchトリガーを設定して、新しいリードをバッチでエクスポートします。
SnowflakeのUpsert rows batchアクションを使用し、Salesforceからのリードのリストの出力データピルをRows source list入力にマッピングして、新しいレコードをアップサートします。
SQL Serverコネクタのアクション
Workatoは、さまざまなアクションを使用してSQL Serverへのデータロードを包括的にサポートします。これらのアクションにより、レコードの挿入、更新、アップサート、削除を効率的に行うことができます。詳細な手順については、以下のアクションを参照してください:
- 行を選択するバッチアクション
- カスタムSQLを使用して行を選択するバッチアクション
- 行を挿入するアクション
- 複数の行を挿入するバッチアクション
- 行を更新するアクション
- 複数の行を更新するバッチアクション
- 行をアップサートするアクション
- 複数の行をアップサートするバッチアクション
- 複数の行を削除するバッチアクション
- 複数の行をレプリケートするバッチアクション
- オンプレミスのファイルからバルクロードするアクション
- カスタムSQLを実行するアクション
- カスタムSQLを使用して長いクエリを非同期で実行するアクション
- ストアドプロシージャを実行するアクション
- クエリ結果をエクスポートするアクション
サンプルレシピ:SalesforceからオンプレミスのSQL Serverへの一括データ取得
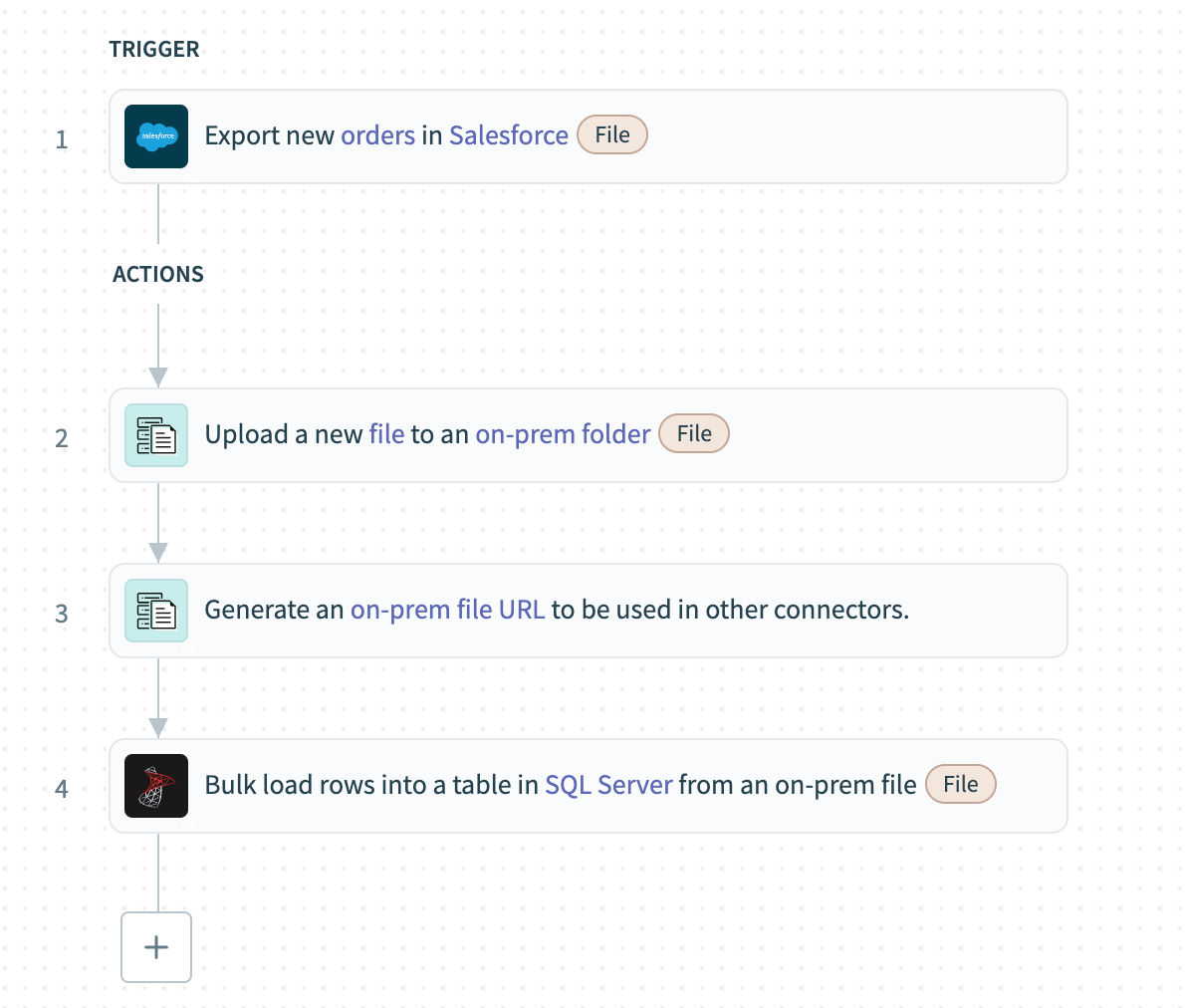
次の例では、一括取得を使用してSalesforceから受注データを抽出し、オンプレミスのSQL Serverにロードします。
 Bulk fetch from Salesforce cloud and load to on-prem SQL Server
Bulk fetch from Salesforce cloud and load to on-prem SQL Server
レシピの解説
**Export new records in Salesforce (bulk)**トリガーを設定し、Salesforceから新しく作成されたレコードをCSVデータとして一括取得します。
On-prem files - Upload fileアクションを使用して、CSVデータをオンプレミスのフォルダにロードします。
On-prem files - Generate on-prem file URLアクションを使用して、オンプレミスシステムに作成されたCSVファイルのURLを生成します。
前のステップで生成されたURLをSQL Server - Bulk load from an on-prem fileアクションにマッピングします。このアクションはオンプレミスフォルダからファイルを取得し、直接テーブルにロードします。
サンプルレシピ:SQL ServerからAmazon S3への一括データロード
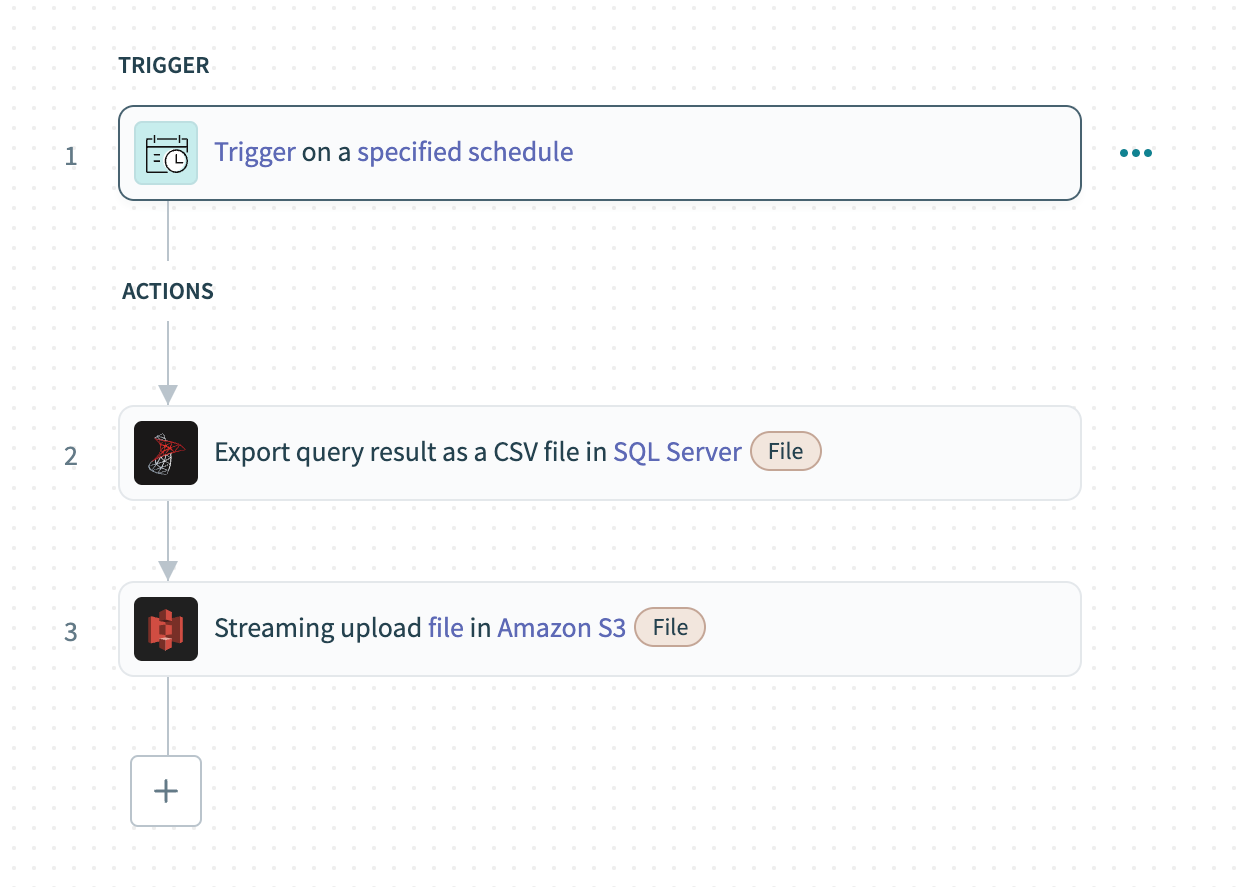
次の例では、一括ロードを使用してSQL Serverからデータを抽出し、Amazon S3にロードします。
 Bulk load data from SQL Server to Amazon S3
Bulk load data from SQL Server to Amazon S3
レシピの解説
Schedulerトリガーを設定し、データの一括ロードの頻度を決定します。
SQL ServerのExport query resultアクションを使用して、データベース上でカスタムSQLクエリを実行し、結果をCSVファイルとして一括エクスポートします。
前のステップからのファイルの内容をAmazon S3のUpload file streamingアクションにマッピングし、データをストリーミングしてクラウドストアにアップロードします。
サポートされているコネクタ
以下のコネクタは一括アップロードをサポートしています:
すべてのファイルコネクタ:
- On-prem files
- Workato FileStorage
- SFTP
- FTP/FTPS
- Google Drive
- Microsoft OneDrive
- Microsoft Sharepoint
- Box
- Dropbox
- BIM 360
- Egnyte
すべてのデータレイクコネクタ:
増分ロード
増分ロードを使用して、フルロードのオーバーヘッドなしにターゲット先のデータを最新の状態に維持します。これは、タイムスタンプ、バージョンキー、トリガーなどを通じてソースデータの変更を追跡し、前回のロード以降に追加または変更されたデータのみをロードすることを含みます。この戦略は、リアルタイムのデータオーケストレーションとシステムリソースへの影響を最小限に抑えるために不可欠です。
Last updated: