Extract data
Data extraction enables you to retrieve information from different applications. Workato supports both bulk and batch extraction, which are essential for ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes.
Event or trigger-based extraction
Event-driven or trigger-based extraction in Workato allows data to be extracted automatically when specific events occur in source systems. This approach is ideal for scenarios where data must be processed immediately after an event, such as creating or updating a record.
You can configure event-driven or trigger-based data extraction to monitor events in real-time or at specified intervals. This ensures timely data capture and processing, keeps your data up to date, supports real-time analytics, and triggers automated workflows with minimal latency.
Use event or trigger-based extraction to extract data in bulk or batches from the following sources:
SaaS
SaaS applications store critical business data in the cloud, including customer, sales, and operational information. You can use Workato to extract this data based on events or schedules to synchronize it with data warehouses, analytics platforms, and other applications.
Sample recipe: Batch extraction from Salesforce
This example demonstrates how to batch extract new or updated records from Salesforce and load them into Snowflake.
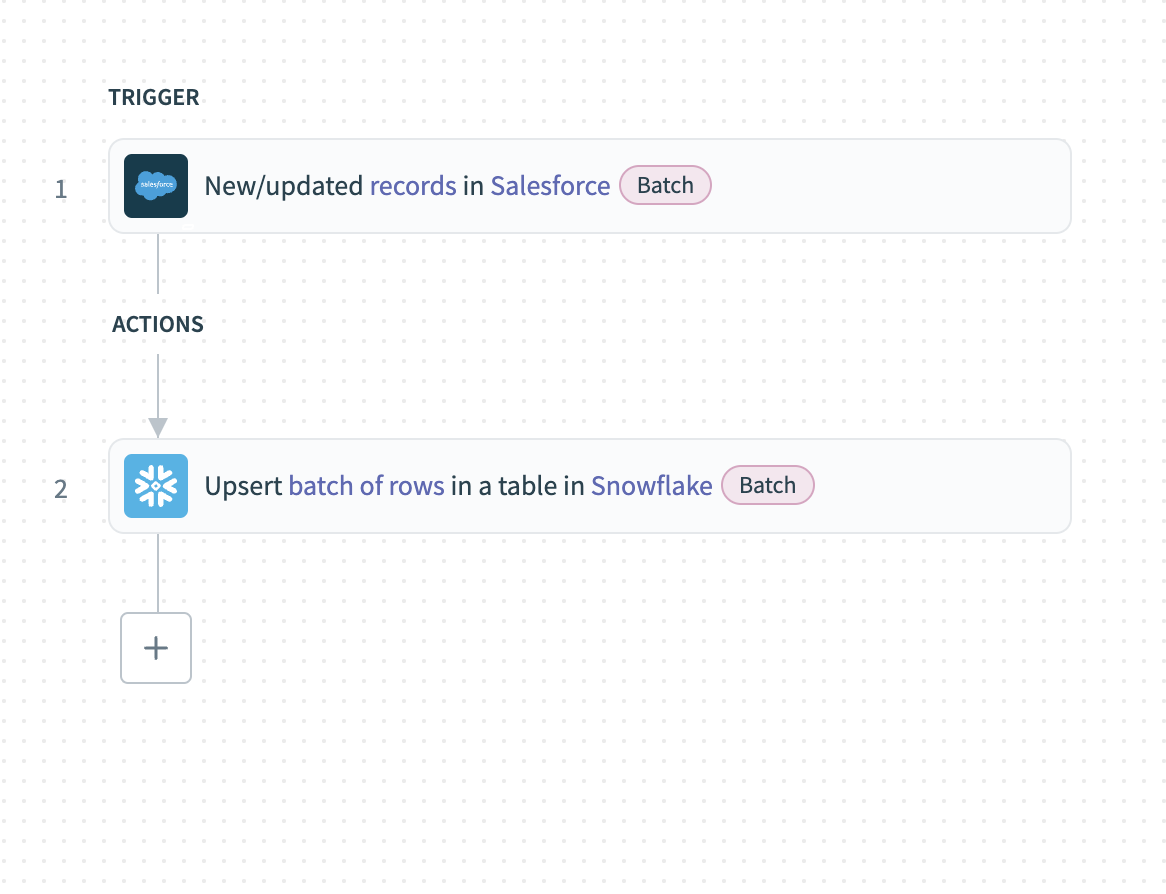 Batch extraction from Salesforce
Batch extraction from Salesforce
Complete the following steps to extract Salesforce records in batches and load them into Snowflake:
Configure the New/updated records in Salesforce batch trigger.
Choose the Object that contains the data you plan to extract. For example, select Account to extract new or updated account records.
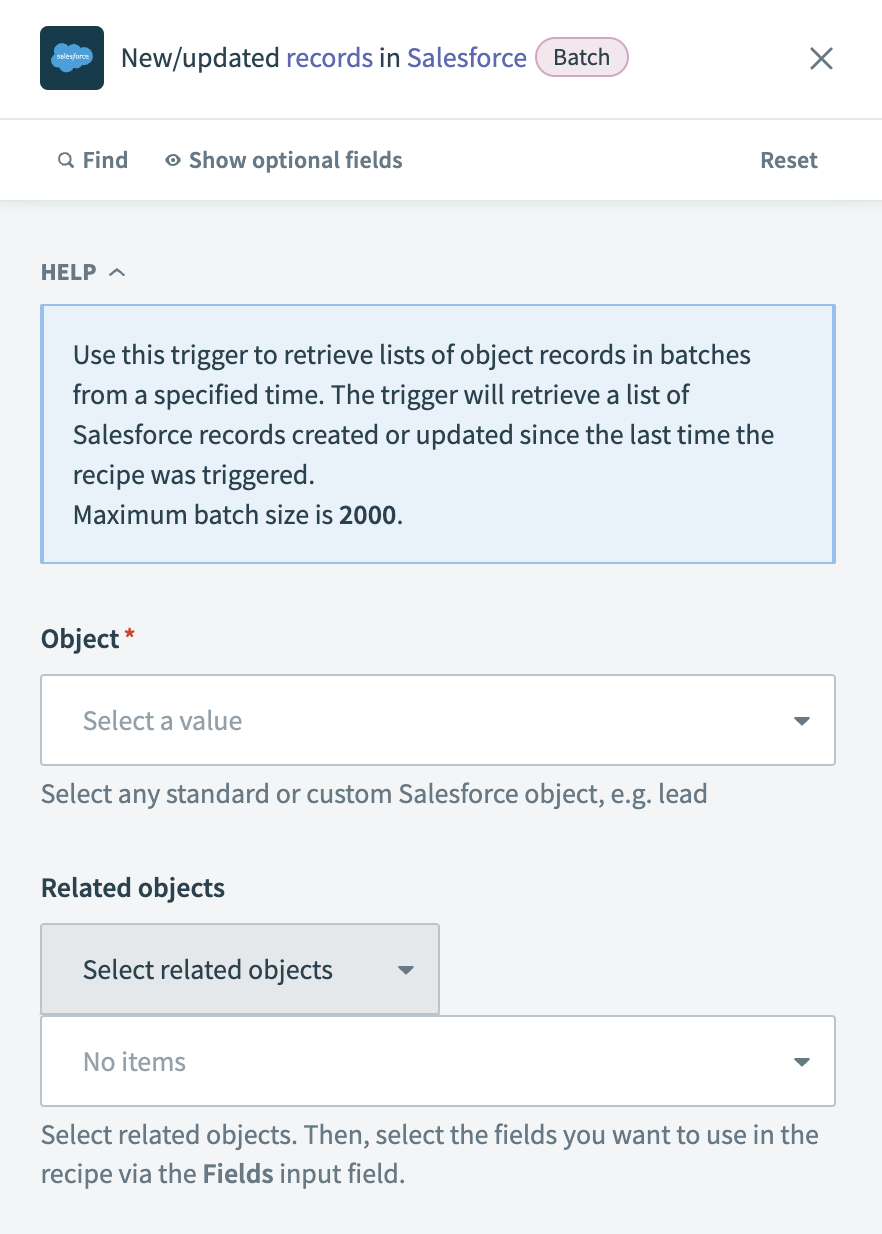 Configure the New/updated records batch trigger
Configure the New/updated records batch trigger
Optional. Choose Related objects to extract additional fields. After you select related objects, specify the fields to retrieve.
Select specific Fields to retrieve to improve performance. If left blank, Workato retrieves all fields.
Optional. Enter a SOQL query in the SOQL WHERE clause field to refine results. For example, you can use the query StageName = 'Closed Lost' AND IsClosed = false to extract records where StageName is set to Closed Lost and IsClosed is false. This retrieves deals marked as lost but not fully closed, allowing further processing.
Optional. Set the Batch size to control how many records are extracted in each batch. The maximum number of records per batch is 2,000, but Workato may reduce this limit depending on the record size. The default batch size is 100.
Optional. Use the Detect new or updated custom data field to specify whether to include newly added or modified custom fields in the trigger output.
Choose the starting point for data extraction in the When first started, this recipe should pick up events from field. Select a relative time or a specific date and time. You can't change this value after you run or test the recipe.
Configure the Upsert rows action.
Choose the Snowflake Table where Workato upserts the extracted records. If the table is not listed, enter the table name manually.
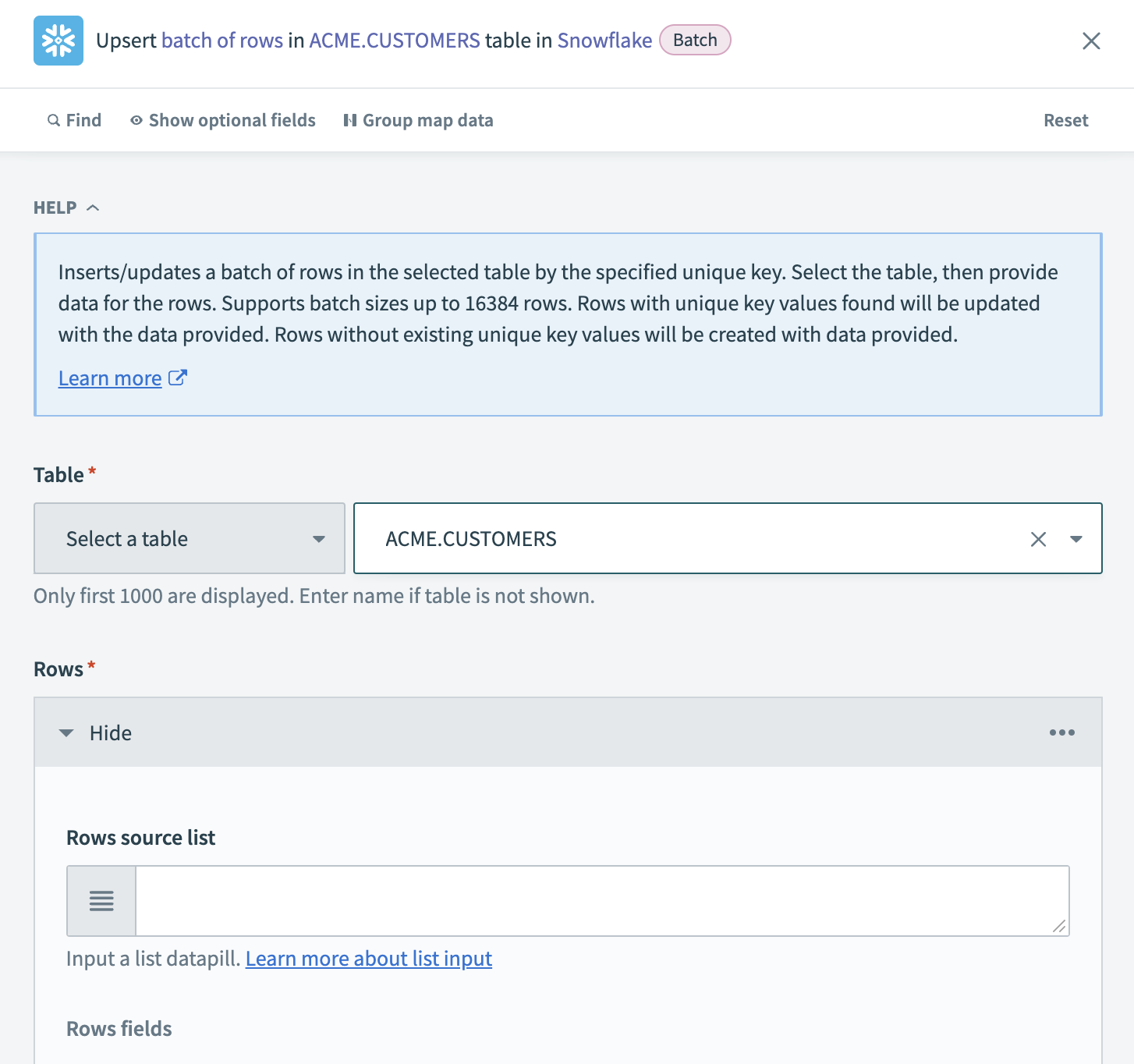 Configure the Upsert rows batch action
Configure the Upsert rows batch action
Map the list datapill for your specified object in the Rows source list field. For example, if extracting accounts in batches from Salesforce, map the AccountsStep 1 datapill. After mapping a list datapill, map each corresponding datapill from Salesforce to the appropriate Rows fields in the Snowflake action.
Optional. Choose a Unique key column to deduplicate rows. This improves performance and ensures Workato updates existing records instead of creating duplicates. Performance can be improved if the unique key is indexed.
Databases
Databases store structured data essential for analytics, reporting, and operational processes. Workato enables you to extract, transform, and load (ETL) or extract, load, and transform (ELT) data from databases into cloud storage, data warehouses, and other applications.
Workato supports two primary database extraction methods:
The following examples demonstrate how to extract data from PostgreSQL and load it into Snowflake using both methods.
Sample recipe: Scheduled bulk extraction from a database
This example demonstrates how to bulk extract large datasets from PostgreSQL and load them into Snowflake. Bulk extraction transfers data at scheduled intervals to improve efficiency and optimize performance for analytics and reporting.
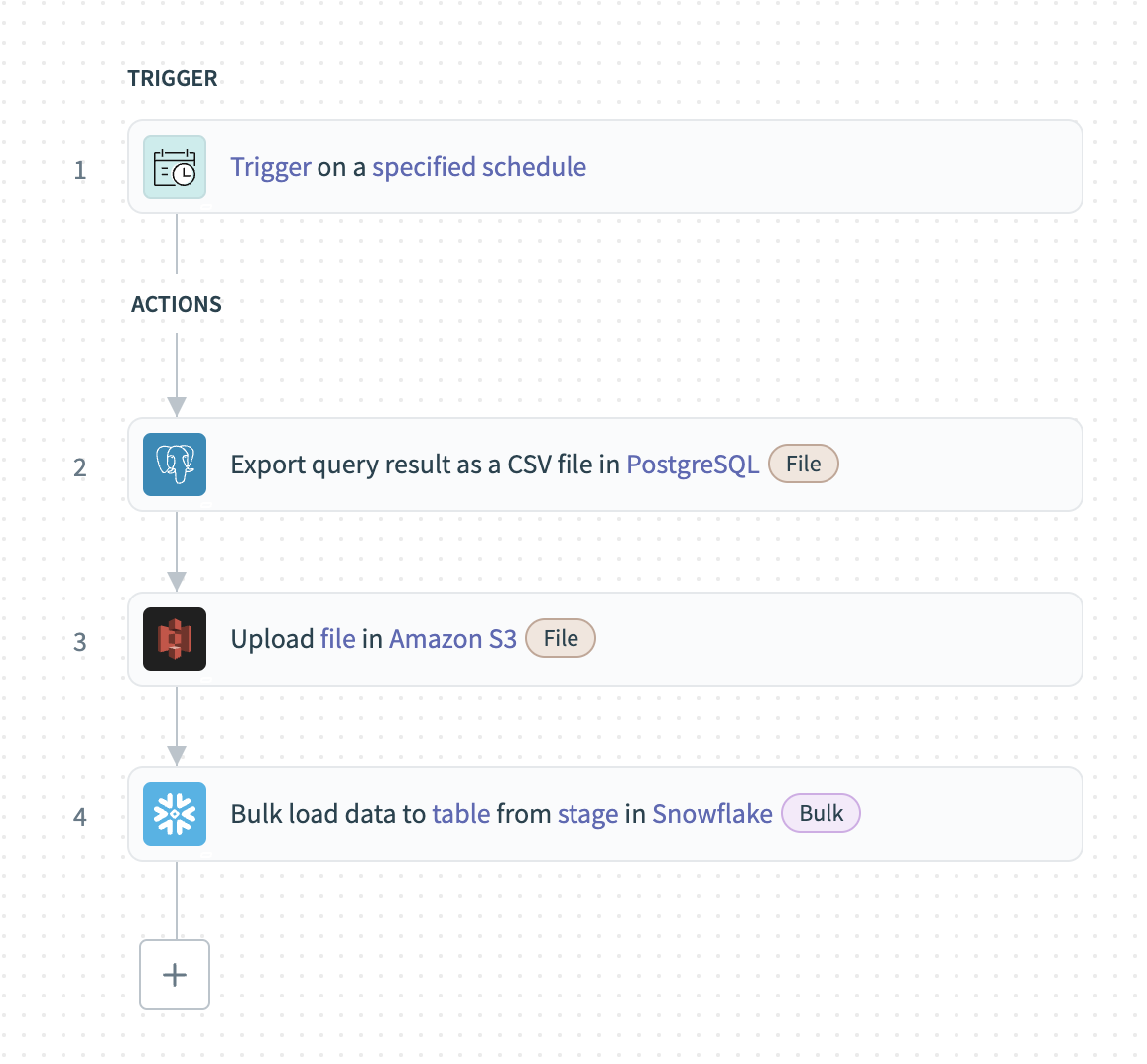 Bulk extraction from PostgreSQL
Bulk extraction from PostgreSQL
Complete the following steps to extract PostgreSQL records in bulk and load them into Snowflake:
Configure a Scheduler trigger to define how often Workato extracts data.
Configure the Export query result bulk action
Define a SELECT query to retrieve the required data in the SQL field. For example, the following query extracts account records updated in the last 24 hours:
SELECT id, name, updated_at FROM accounts WHERE updated_at >= NOW() - INTERVAL '1 day'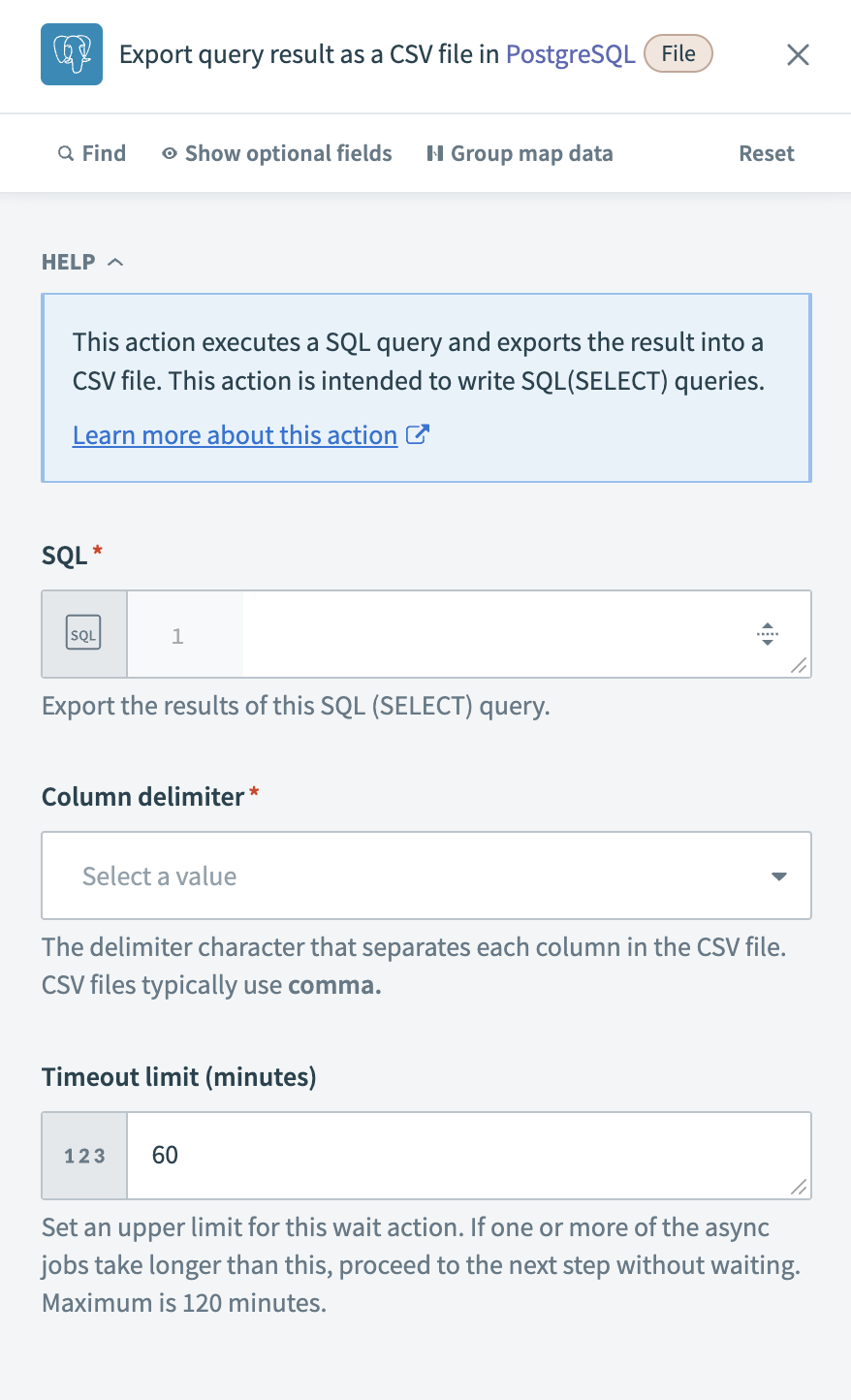 Configure the Export query result action
Configure the Export query result action
Choose a Column delimiter to separate values in the exported CSV file. The most common option is comma (,), but you can select other delimiters based on system requirements.
Define the Timeout limit (minutes) for the action. If the query execution exceeds this limit, Workato proceeds to the next step. The default value is 60 minutes, with a maximum limit of 120 minutes.
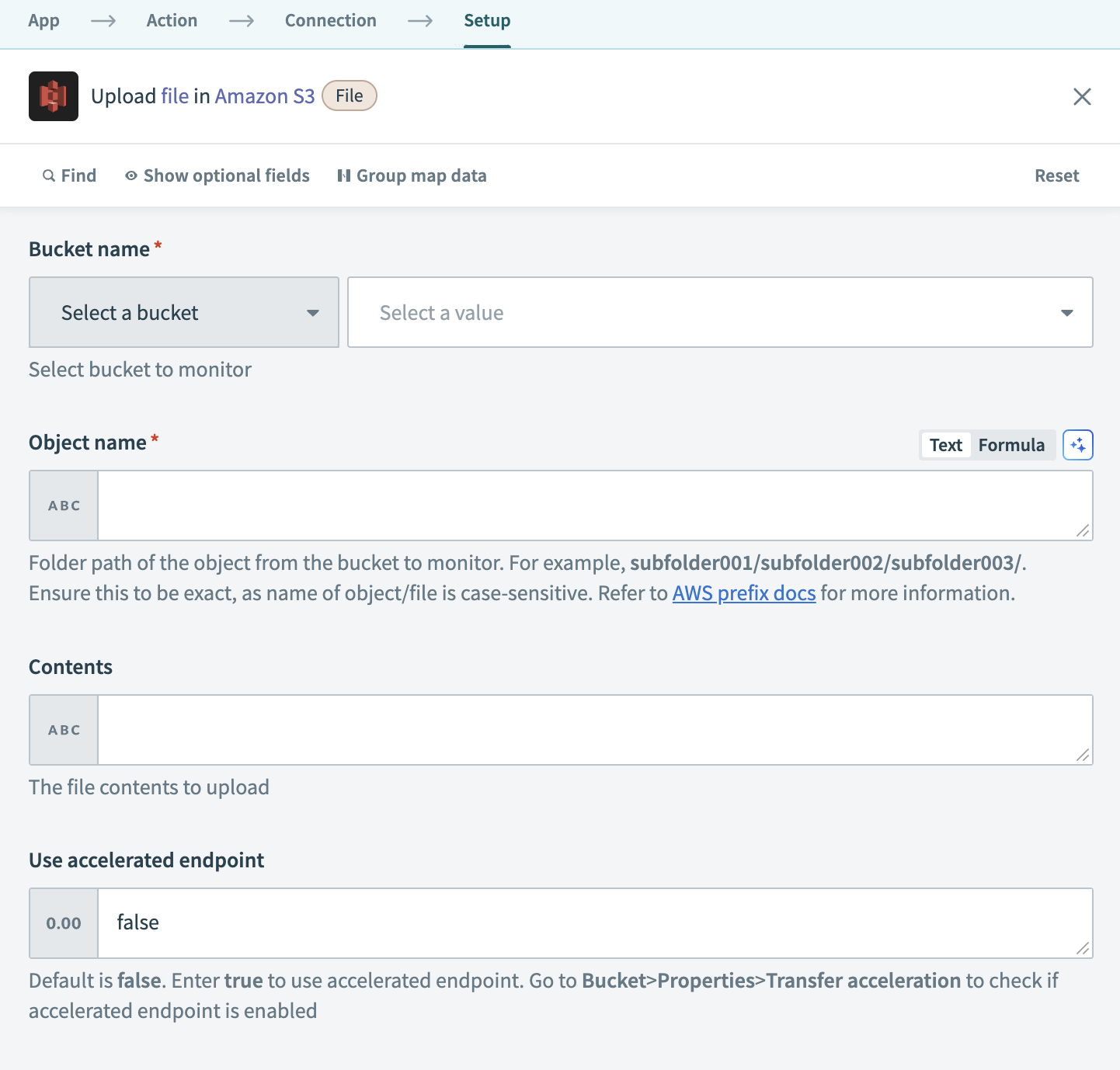
Configure the Amazon S3 Upload file action
Select the bucket where you plan to upload the file from the Bucket name drop-down menu.
 Configure the Upload file action
Configure the Upload file action
Define the path where you plan to upload the file in the Object name field. For example, subfolder001/subfolder002/filename.csv saves the file in subfolder002 inside subfolder001 within the selected bucket. This field is case-sensitive.
Map the PostgreSQL File contentsStep 2 datapill to the Contents field.
Optional. Set the Use accelerated endpoint field to true to use S3 transfer acceleration, which speeds up file uploads over long distances. Ensure the target bucket has Transfer acceleration enabled in AWS.
Optional. Choose a Canned ACL to define access permissions for the uploaded file.
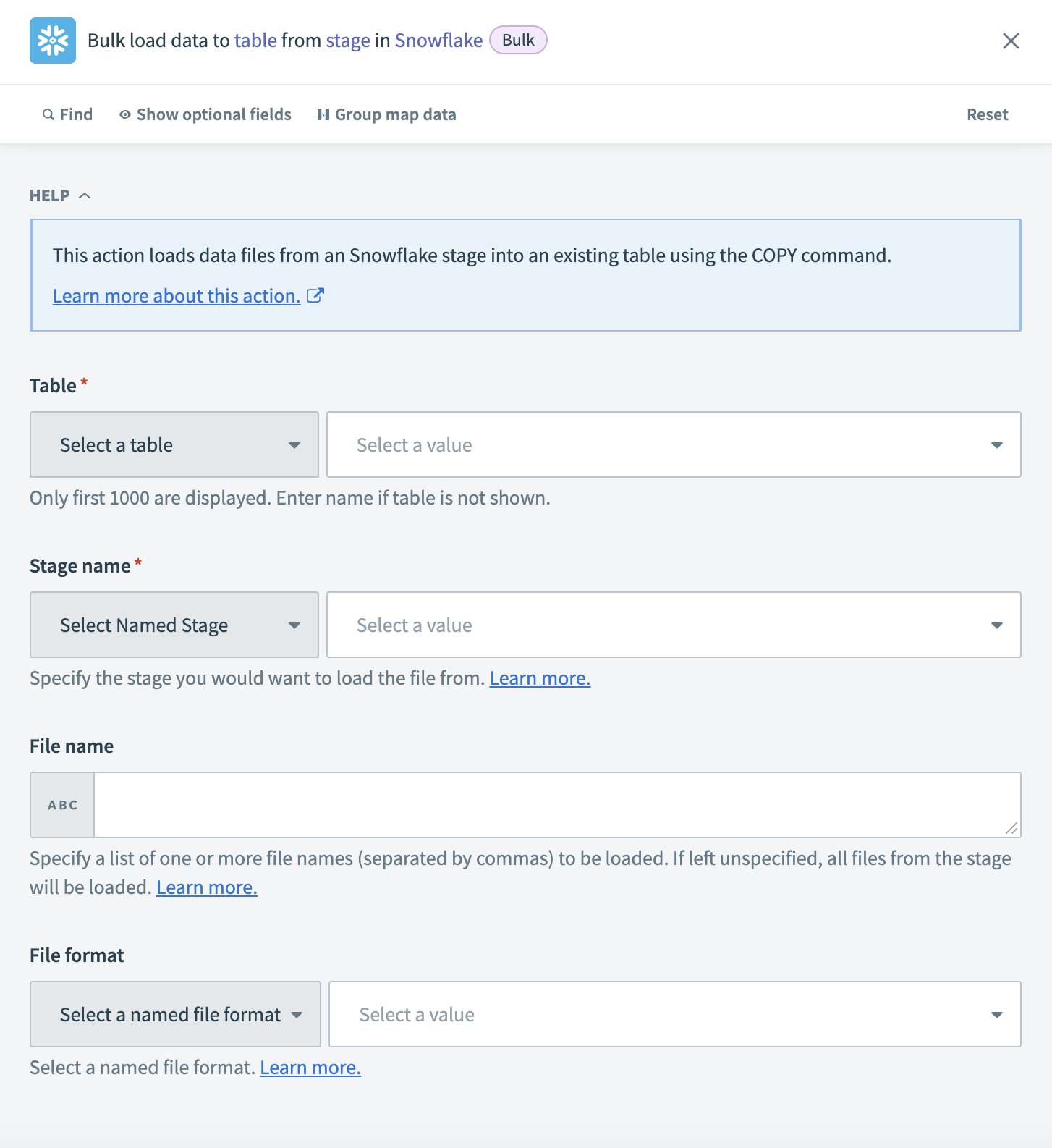
Configure the Bulk load to table from stage action
Choose the Table where Workato loads the extracted data. If the table is not listed, enter the table name manually.
 Configure the Bulk load to table from stage action
Configure the Bulk load to table from stage action
Choose the Stage name that references the Amazon S3 location where the files are stored.
Enter a list of file names (comma-separated) in the File name field to load specific files from S3. If left blank, Workato loads all files from the selected stage.
Select a File format that matches the structure of the uploaded files.
Sample recipe: Batch extraction from a database
This example demonstrates how to extract new or updated records from PostgreSQL in batches and load them into Snowflake.
 Batch extraction from PostgreSQL
Batch extraction from PostgreSQL
Complete the following steps to extract PostgreSQL records in batches and load them into Snowflake:
Configure the New/updated batch of rows in PostgreSQL trigger
Choose the Table that contains the records you plan to extract. If the table is not listed, enter the table name manually.
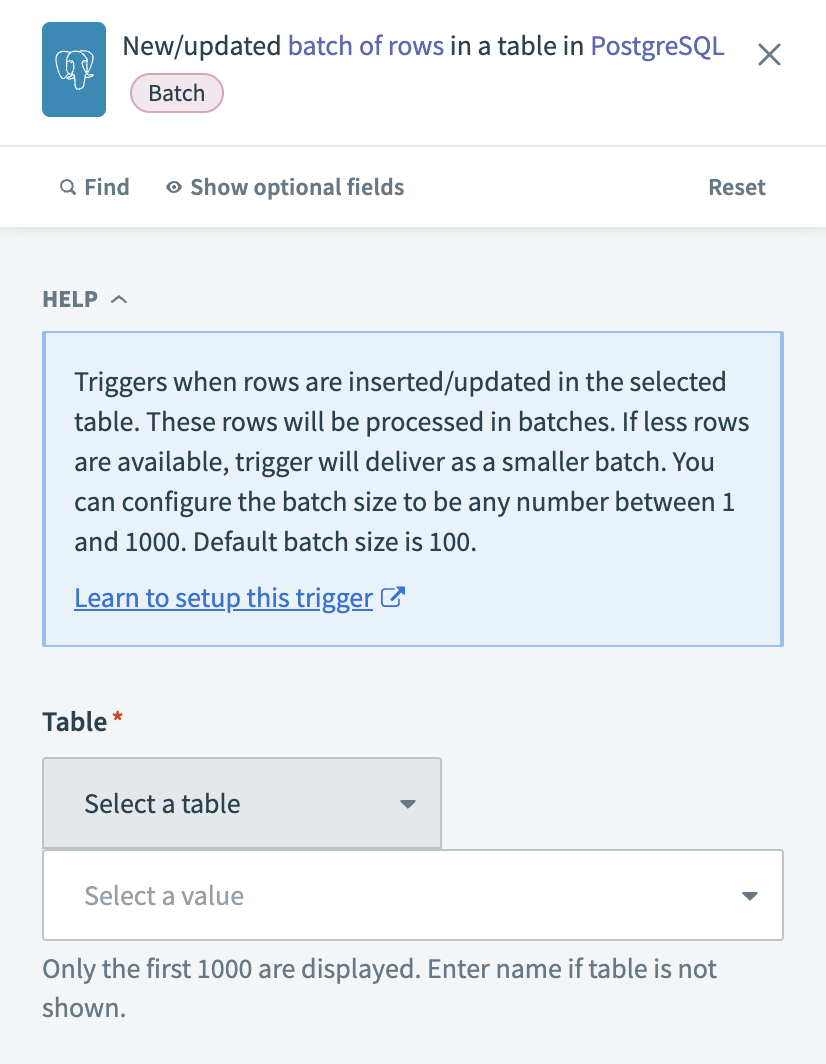 Configure the New/updated batch of rows in PostgreSQL trigger
Configure the New/updated batch of rows in PostgreSQL trigger
Select a Unique key column to deduplicate rows. Use a primary key or a column with a unique constraint to ensure no trigger events are missed. Indexing the column improves performance.
Select a Sort column to identify updated rows. Only timestamp columns are supported. Use a high-precision timestamp (up to milliseconds) to prevent missing updates that occur in rapid succession.
Enter the number of rows to return in each batch in the Batch size field. The default is 100, and the maximum is 1,000.
Optional. Choose Output columns to specify the columns to retrieve. Leave blank to retrieve all columns.
Optional. Define an SQL WHERE condition to filter records. For example, currency = 'USD' filters records where the currency field is USD. Ensure string values are enclosed in single quotes (').
Configure the Snowflake Upsert rows batch action
Choose the Table where you plan to upsert the extracted records. If the table is not listed, enter the table name manually.
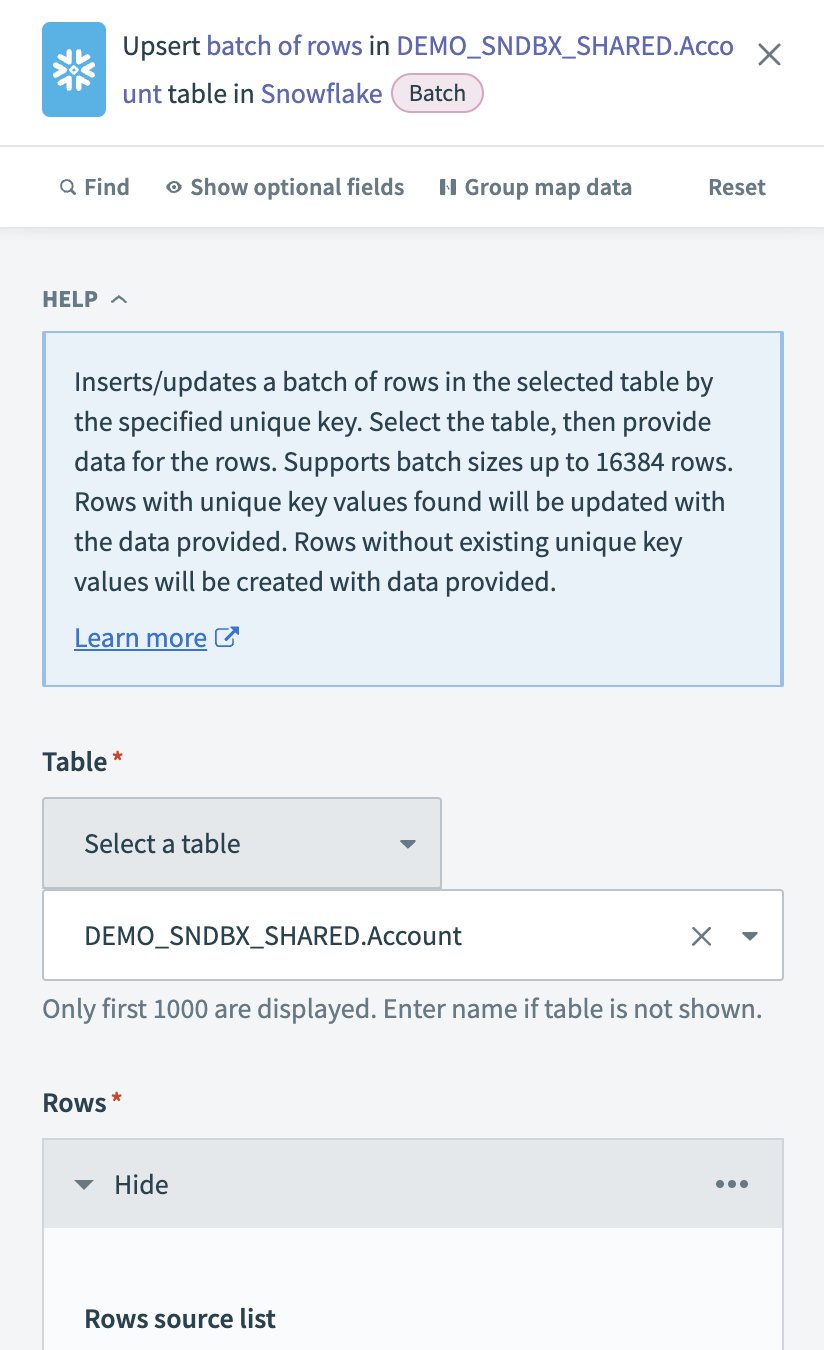 Configure the Snowflake Upsert rows batch action
Configure the Snowflake Upsert rows batch action
Input a list datapill that contains records extracted from PostgreSQL in the Rows source list field. This defines the batch of rows to upsert. Workato automatically retrieves available fields from the selected table. You can map the corresponding datapills to match the schema.
Choose a Unique key column to prevent duplicate records. Use a primary key or an indexed column to improve performance.
File systems
File connectors in Workato enable you to extract data from cloud or on-premises file systems using download actions that support bulk extraction and streaming-compatible processing. These actions move data seamlessly into databases, data warehouses, or applications.
You can also combine download actions with bulk actions in app connectors to extract files and transfer them as complete datasets.
Supported connectors
The following connectors support bulk downloads:
Sample recipe: Bulk extract from FileStorage and load to Snowflake
This example demonstrates how to extract files from Workato FileStorage and load them into a Snowflake table for further processing. Bulk extraction ensures efficient file transfers and seamless data ingestion into a data warehouse.
 Extract data in bulk from FileStorage and load to Snowflake
Extract data in bulk from FileStorage and load to Snowflake
Complete the following steps to extract files from Workato FileStorage and load them into Snowflake:
Configure the New file in Workato FileStorage trigger
Specify the earliest point from which to detect new files in the When first started, this recipe should pick up events from field. Leave this field blank to pick up new files from one hour ago. You cannot change this value after you run or test the recipe.
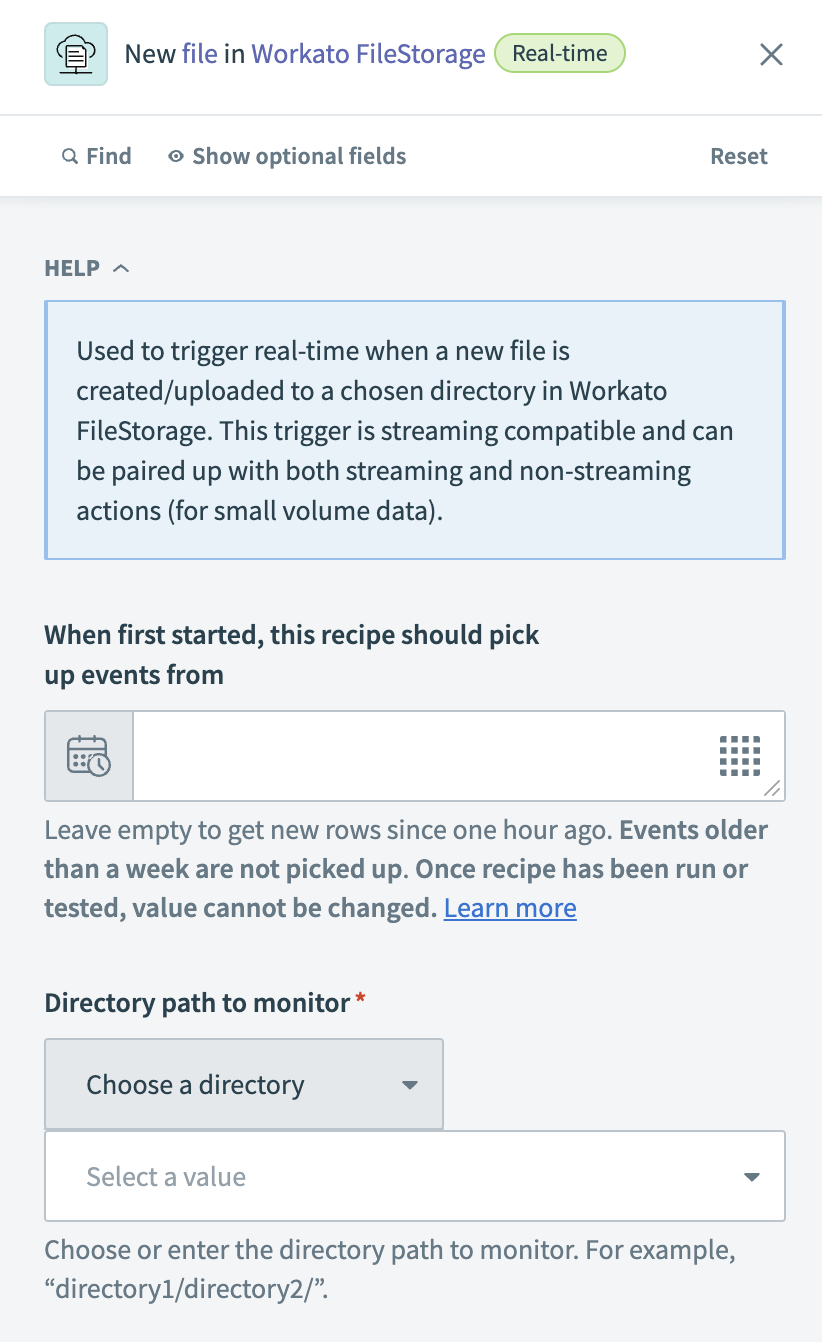 Configure the New file in FileStorage trigger
Configure the New file in FileStorage trigger
Choose or enter the directory path to monitor for new files in the Directory path to monitor field. For example, directory1/directory2/.
Choose whether to monitor subdirectories inside the selected directory in the Include sub-directories? field.
Configure the Upload file to internal stage in Snowflake
Choose how to access the file data in the Source Type field.
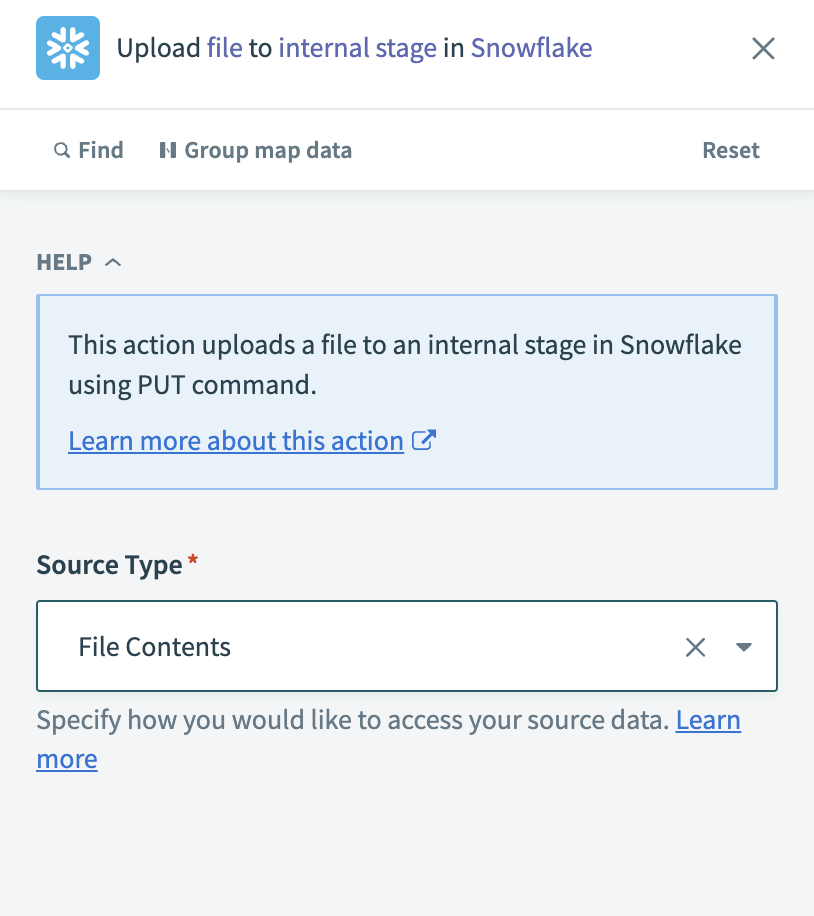 Configure the Upload file to internal stage action
Configure the Upload file to internal stage action
Map the Workato FileStorage File contentsStep 1 datapill to the File Contents field.
Specify the Internal stage you plan to load the file into.
Select whether Snowflake should replace an existing file with the same name in the Overwrite field.
Choose whether to apply gzip compression during the upload process in the Auto Compress field.
Sample recipe: Bulk extract data from SFTP to Snowflake
This example demonstrates how to extract data in bulk from an SFTP server and load it into Snowflake.
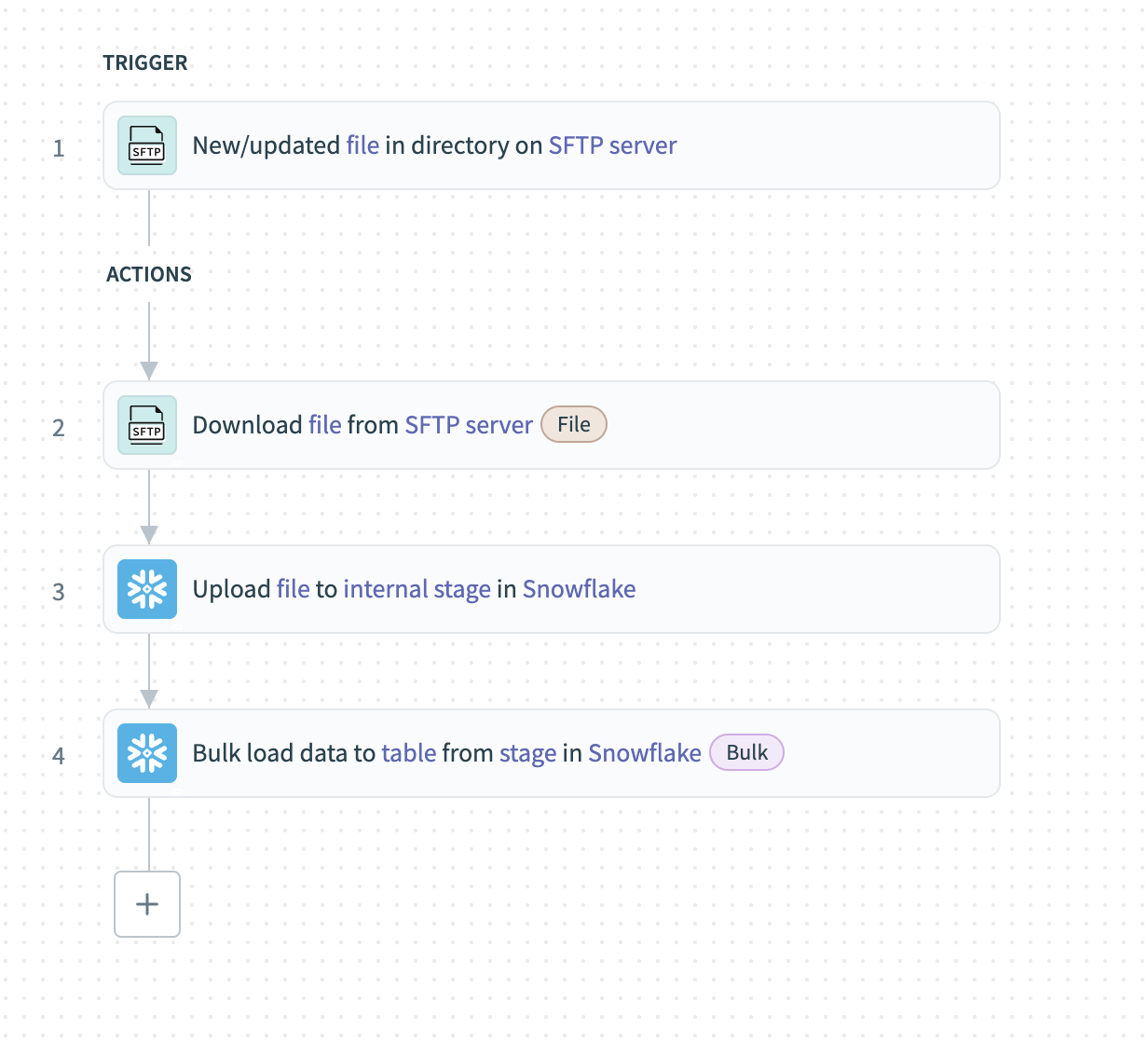 Extract data in bulk from SFTP and load to Snowflake
Extract data in bulk from SFTP and load to Snowflake
Complete the following steps to extract data from SFTP and load it into Snowflake:
Configure the New/updated file in directory trigger
Enter the Directory path on the SFTP server to monitor for new or updated files. Files in this directory are processed in ascending order based on modification time.
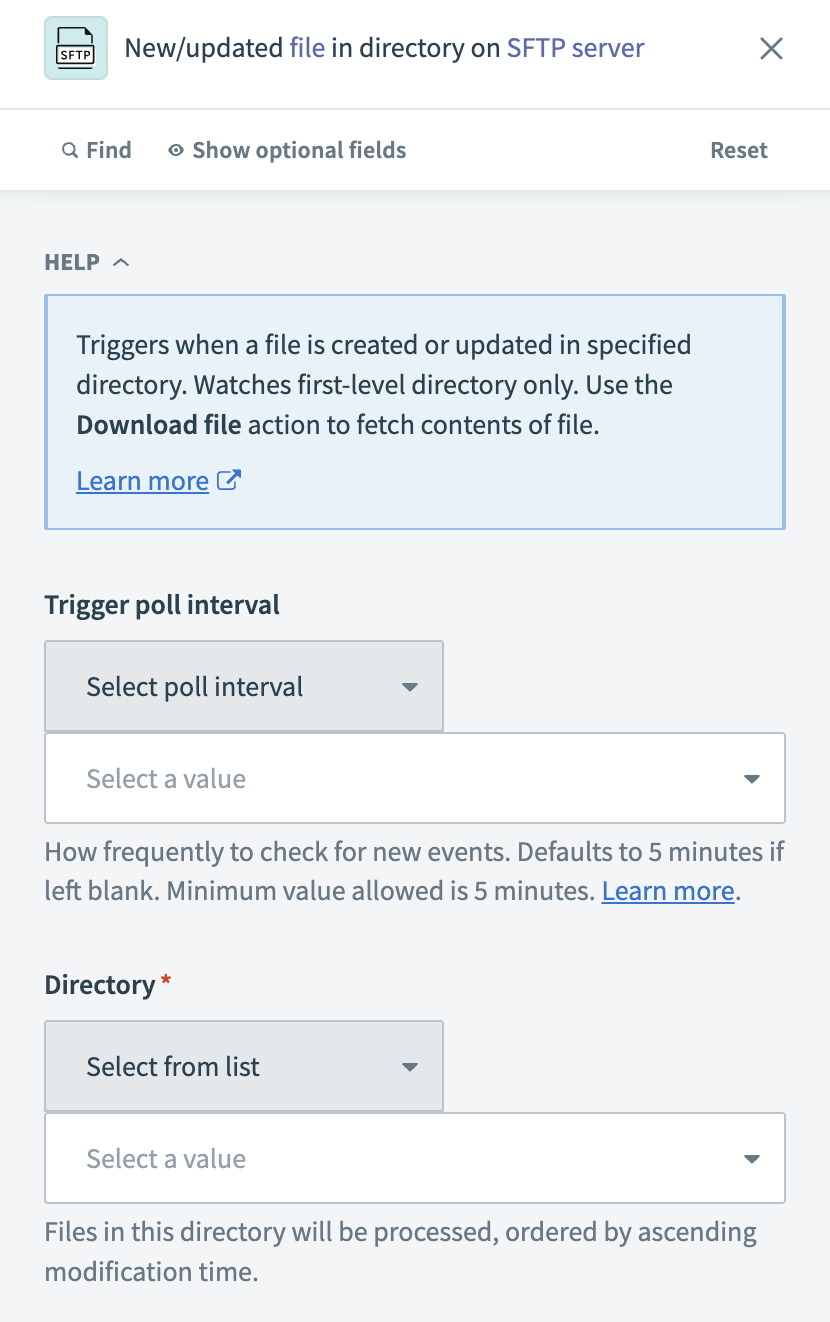 Configure the New/updated file in directory trigger
Configure the New/updated file in directory trigger
Specify the earliest point from which to detect new files in the When first started, this recipe should pick up events from field. You can't change this value after running or testing the recipe.
Configure the Download file action
Specify the File path of the file you plan to download from the SFTP server.
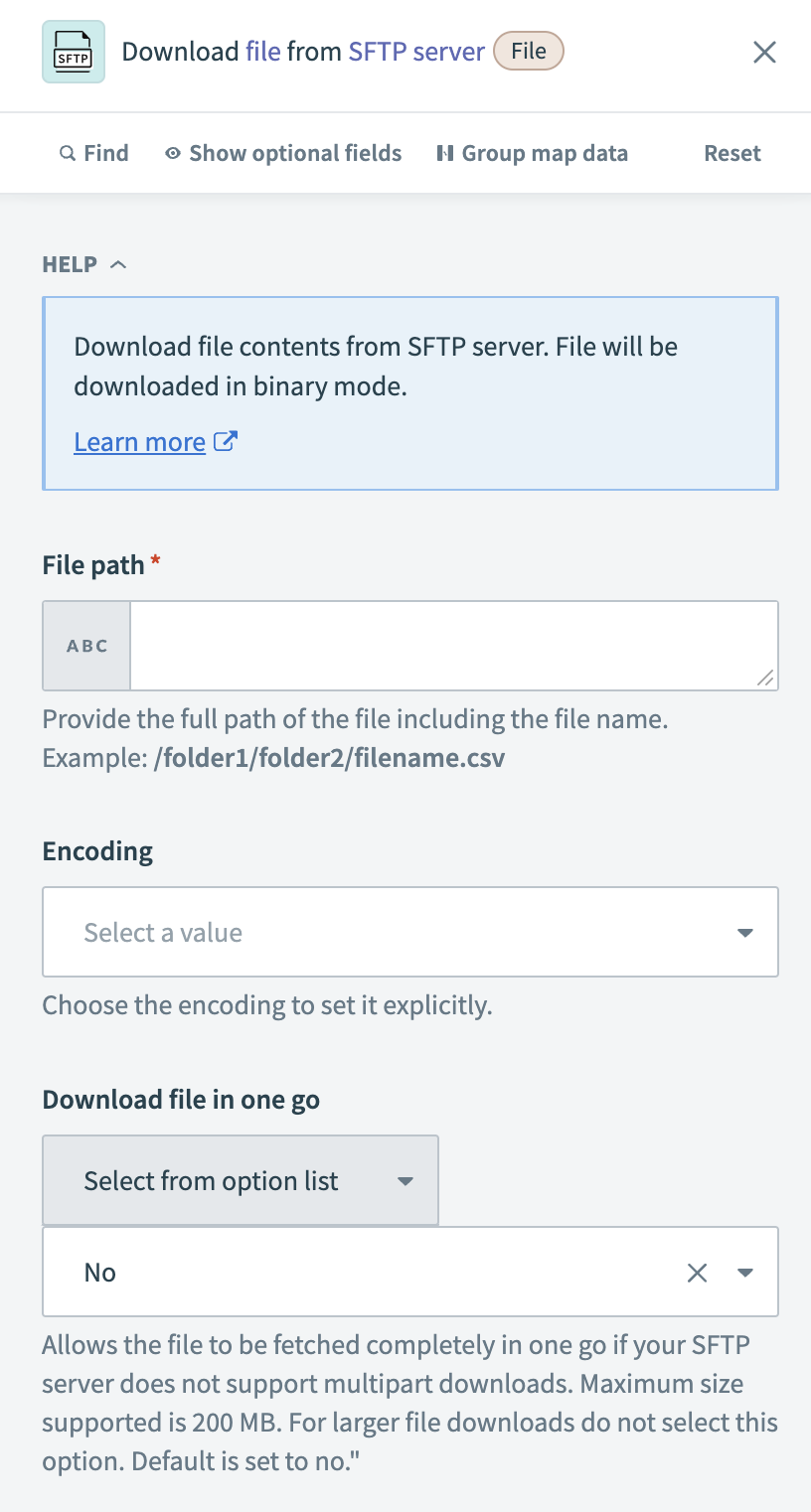 Configure the Download file action
Configure the Download file action
Optional. Choose the Encoding format if the file requires a specific character encoding, such as UTF-8, ISO-8859-1.
Optional. Choose whether to download the file in a single operation or in multiple parts in the Download file in one go field.
Configure the Upload file to internal stage action
Specify how Workato accesses the file data in the Source Type field.
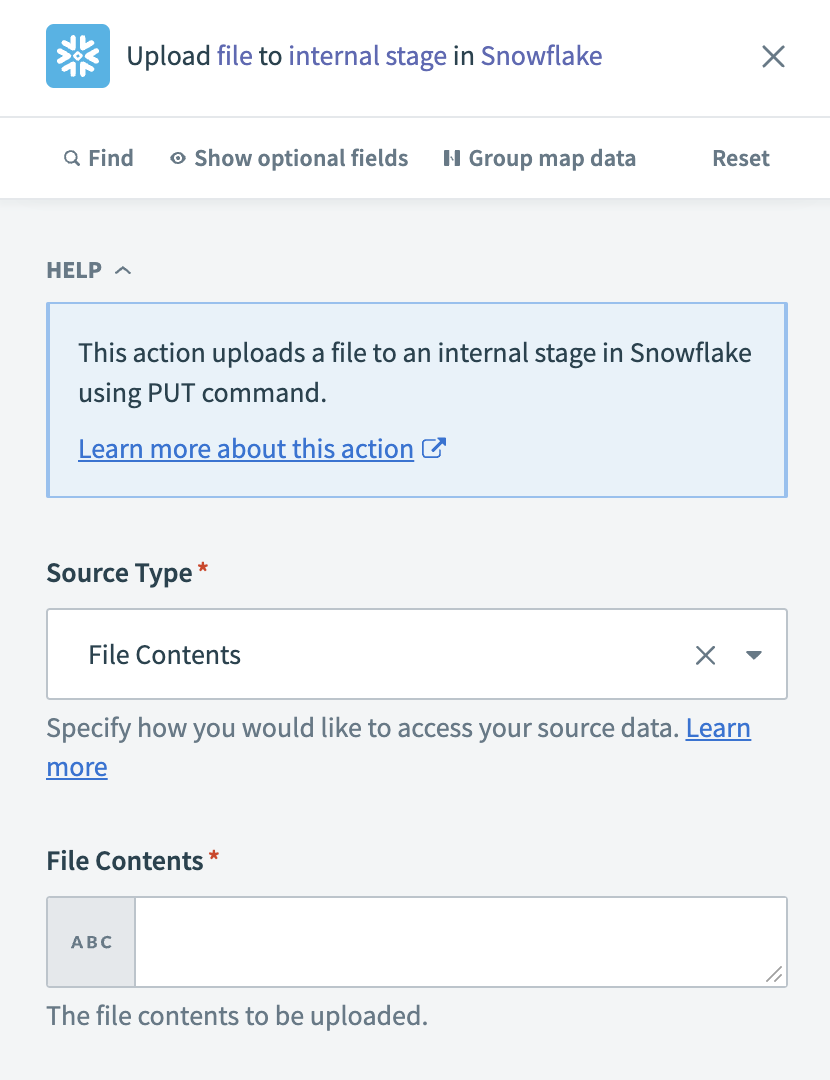 Configure the Upload file to internal stage action
Configure the Upload file to internal stage action
Map the SFTP File contentsStep 2 datapill to the File Contents field.
Select the Snowflake Internal stage where the file is uploaded.
Optional. Choose whether Snowflake should replace an existing file with the same name in the Overwrite field.
Optional. Choose whether Snowflake should apply gzip compression to the file during upload in the Auto Compress field.
Configure the Bulk load data to table from stage action
Choose the Snowflake Table where you plan to load the data.
 Configure the Bulk load data to table from stage action
Configure the Bulk load data to table from stage action
Select the Snowflake Stage name where the uploaded files are stored.
Optional. Enter specific file names (comma-separated) in the File name field to load only selected files. If left blank, Workato loads all files from the stage.
Optional. Choose the File format that matches the structure of the uploaded files, such as CSV, JSON, or PARQUET.
Custom extraction
Custom extraction in Workato enables you to define specific criteria to pull data using custom queries or scripts. This method offers flexibility for complex data scenarios where standard triggers and actions do not apply. However, custom extraction may require careful attention to maintenance, performance, resource usage, error handling, and security.
Last updated: